You can find more details on where these challenges come from and how/why we will be approaching them in the original posting.
Challenge #3
The original link to the challenge (in French) can be found here. The idea is to consider an empty three-by-three grid, and then place two 1s in any two of the nine cells:

The grid is the completed as follows:
- pick any empty cell
- fill it as the sum of all its neighbors (diagonals as well)
I've here detailed an example, the new cell is indicated at each step in red:

The challenge is now to find a way to complete the grid in such a manner as to obtain the greatest value in a cell. In the previous example, the maximum obtained was 30, can we beat it?
Power grid
I strongly encourage you to try out a few grids before continuing to read. Any guesses as to what the greatest obtainable value is?
As you try it out, you might realize that the middle cell is rather crucial, as it can contribute its value to every other cell, thus offering the following dilemma:
- fill it too soon and it will be filled with a small value
- fill it too late and it will not be able to distribute its value to a sufficient number of other cells
Gotta try them all!
In the spirit of our previous posts, let's try all possibilities and perform an exhaustive search.
The first thing we need to ask ourselves is the number of possible ways of filling up the square, and then generating all those combinations in R.
Ignoring how the cells are filled up, there are 9 possibilities to fill up the first cell (with a 1), 8 possibilities for the second (also a 1), 7 for the third (with the rule)... and 1 for the ninth final cell. Which amounts to 9*8*7*...*1 = 9! = 362880, piece of cake for R to handle.
Generating permutations
So we want to generate all these possibilities which are actually permutations of numbers 1 through 9, where each number corresponds to a cell. {7,1,5,2,4,9,3,8,6} would mean filling up cells 7 and 1 first with a 1, then filling up cell #5, then #2 and do on.
A naive method would be to use expand.grid() once again for all digits one through 9, which would also give unacceptable orders such as {7,1,5,2,1,3,6,8,9} because cell #1 is filled twice at different times! We could easily filter those out by checking if we have 9 unique values. But this would amount to generating all 9*9*9..*9=9^9>=387 million combinations and narrow down to just the 362K of interest. That seems like a lot of wasted resources and time!
Instead, I approached the problem from a recursive perspective (R does have a package combinat that does this type of work, but here and in general in all the posts I will try to only use basic R):
In R:
SmartPermutation <- function(v) {
if (length(v) == 1) {
return(as.data.table(v))
} else {
out <- rbindlist(lapply(v, function(e) {
tmp <- SmartPermutation(setdiff(v, e))
tmp[[ncol(tmp) + 1]] <- e
return(tmp)
}))
return(out)
}
}

Neighbors <- function(i) {
neighbor.list <-
list(c(2, 4, 5), c(1, 3, 4, 5, 6), c(2, 5, 6),
c(1, 2, 5, 7, 8), c(1, 2, 3, 4, 6, 7, 8, 9), c(2, 3, 5, 8, 9),
c(4, 5, 8), c(4, 5, 6, 7, 9), c(5, 6, 8))
return(neighbor.list[[i]])
}
CompleteGrid <- function(row) {
grid <- rep(0, 9)
grid[row[1 : 2]] <- 1
for (i in 3 : 9) {
grid[row[i]] <- sum(grid[Neighbors(row[i])])
}
return(max(grid))
}
Final answer
Based on our exhaustive search, we were able to identify the following solution yielding a max value of...57!

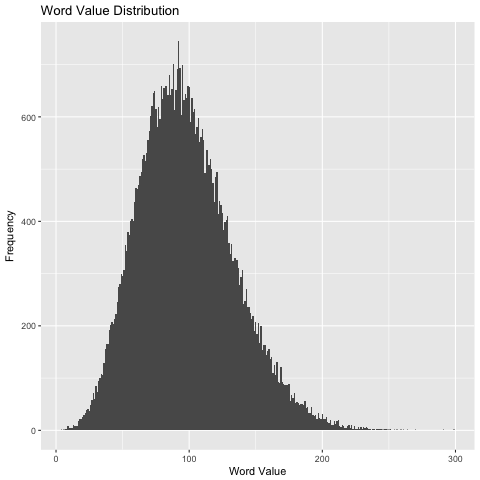
Little bonus #1: Distribution
The natural question is around the distribution of values? Were you also stuck around a max value in the forties? 57 seems really far off, but the distribution graph indicates that reaching values in the forties is already pretty good!

Little bonus #2: Middle cell
Do you remember our original trade-off dilemma? How early should the middle cell be filled out? In the optimal solution we see it was filled out exactly halfway through the grid.
To explore further, I also kept track for each permutation when the middle cell was filled out and what its filled value was. The optimal solution is shown in green, the middle cell being filled out in 5th position with a seven.

And a similar plot of overall max value against position in which the middle cell was filled:

It clearly illustrates the dilemma of filling neither too late nor too early: some very high scores can be obtained when the middle cell is filled as 4th or 6th cell, but absolute max of 57 will only be achieved when it is filled in 5th. Filling it in the first or last three positions will only guarantee a max of 40.
In the spirit of our previous posts, let's try all possibilities and perform an exhaustive search.
The first thing we need to ask ourselves is the number of possible ways of filling up the square, and then generating all those combinations in R.
Ignoring how the cells are filled up, there are 9 possibilities to fill up the first cell (with a 1), 8 possibilities for the second (also a 1), 7 for the third (with the rule)... and 1 for the ninth final cell. Which amounts to 9*8*7*...*1 = 9! = 362880, piece of cake for R to handle.
Generating permutations
So we want to generate all these possibilities which are actually permutations of numbers 1 through 9, where each number corresponds to a cell. {7,1,5,2,4,9,3,8,6} would mean filling up cells 7 and 1 first with a 1, then filling up cell #5, then #2 and do on.
A naive method would be to use expand.grid() once again for all digits one through 9, which would also give unacceptable orders such as {7,1,5,2,1,3,6,8,9} because cell #1 is filled twice at different times! We could easily filter those out by checking if we have 9 unique values. But this would amount to generating all 9*9*9..*9=9^9>=387 million combinations and narrow down to just the 362K of interest. That seems like a lot of wasted resources and time!
Instead, I approached the problem from a recursive perspective (R does have a package combinat that does this type of work, but here and in general in all the posts I will try to only use basic R):
- If I only have one value a, there is only a single permutation:{a}
- If I only have two values a and b, I fix one of the values and look at all permutations I have of the left-over value, then append the value that was fixed:
- fix a, all permutations of b are {b}, then append the a: {b,a}
- fix b, all permutations of a are {a}, then append the b: {a,b}
- the result is {a,b} and {b,a} - with three values, repeat the process now that we know all permutations of 2 values:
- fix a, all permutations of b,c are {b,c} and {c,b}, then append the a: {b,c,a}, {c,b,a}
- fix b, all permutations of a,c are {a,c} and {c,a}, then append the b: {a,c,b}, {c,a,b}
- fix c, all permutations of a,b are {a,b} and {b,a}, then append the c: {a,b,c}, {b,a,c}
In R:
SmartPermutation <- function(v) {
if (length(v) == 1) {
return(as.data.table(v))
} else {
out <- rbindlist(lapply(v, function(e) {
tmp <- SmartPermutation(setdiff(v, e))
tmp[[ncol(tmp) + 1]] <- e
return(tmp)
}))
return(out)
}
}
Computing the score
The next and final step is to fill out the grid for each possible permutation.
This is done by defining a static mapping between cell ID and its neighbors:

We then go through each permutation, fill out a virtual grid (in our case it's not a 3-by-3 but a vector, which doesn't change anything as long as the relationships between neighbors is maintained) and track maximum value.
Neighbors <- function(i) {
neighbor.list <-
list(c(2, 4, 5), c(1, 3, 4, 5, 6), c(2, 5, 6),
c(1, 2, 5, 7, 8), c(1, 2, 3, 4, 6, 7, 8, 9), c(2, 3, 5, 8, 9),
c(4, 5, 8), c(4, 5, 6, 7, 9), c(5, 6, 8))
return(neighbor.list[[i]])
}
CompleteGrid <- function(row) {
grid <- rep(0, 9)
grid[row[1 : 2]] <- 1
for (i in 3 : 9) {
grid[row[i]] <- sum(grid[Neighbors(row[i])])
}
return(max(grid))
}
Final answer
Based on our exhaustive search, we were able to identify the following solution yielding a max value of...57!

Little bonus #1: Distribution
The natural question is around the distribution of values? Were you also stuck around a max value in the forties? 57 seems really far off, but the distribution graph indicates that reaching values in the forties is already pretty good!

Little bonus #2: Middle cell
Do you remember our original trade-off dilemma? How early should the middle cell be filled out? In the optimal solution we see it was filled out exactly halfway through the grid.
To explore further, I also kept track for each permutation when the middle cell was filled out and what its filled value was. The optimal solution is shown in green, the middle cell being filled out in 5th position with a seven.


It clearly illustrates the dilemma of filling neither too late nor too early: some very high scores can be obtained when the middle cell is filled as 4th or 6th cell, but absolute max of 57 will only be achieved when it is filled in 5th. Filling it in the first or last three positions will only guarantee a max of 40.