
Recursion
From the past sections, it clearly appears as if the naïve approaches, despite potentially leading to the correct answer, would require much effort and are not the ideal path to proceed. Let us try to put off counting all possible permutations to later if possible.
Another way to think of the problem is to actually stop and think at what happens whenever a song is played. Only two things can happen: it is either a new song or one already heard.
More formally, denoting by Q(u, p) the probability of having heard u unique songs after p plays:
We can initialize by setting Q(1,1)=1 and Q(i,j)=0 if i>j.
When faced with such recursions, it is often helpful to expand back a few terms and try to see if a certain tendency or pattern emerges. You can try it out for yourself here, things get very messy very quickly with no clear trend in sight.
A little too early to shout victory, but at least we can write a nice recursive R function to quickly compute the P(k|N) probabilities, and no longer have to rely on simulations.
How are our P(k|N) related to the above Q(u,p) probabilities? Recall that P(k|N) is the probability of having listened to all N songs at least once after exactly p=N+k plays and not a song sooner! This means that after N+k-1 plays, we have heard all songs except one at least once, and on the next play we will hear the final elusive song (event that occurs with probability 1/N). Putting the pieces together:

First small victory!

The hidden sequences
Now that we have a way of getting exact probability values, is there any way we could get a glimpse of what the solution looks like?
For a given number of cards (2, 3, 4, ...) we have computed the P(k|N) probabilities. The numbers were quite ugly, but what really interests us is the numerator as the denominator will always be N^(N+k) which is the size of the universe for playing a random sequence of N songs N+k times (and this indeed what we saw when computing P(0|N), P(1|N) and P(k|2) in our first approaches.
Here's are the values corresponding to the numerators:

A quick glance will show that each row is a multiple of N!. Simplifying to make the core structure more apparent yields the following table:
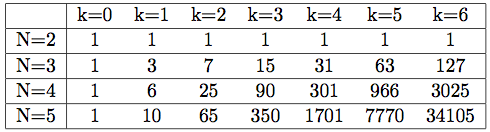
We have now narrowed down our original problem to understanding how each of these sequences is generated. All we need now that is to get the general formula of the terms in previous table, denoting it by S_N(k). We will then have:

The second row (for N=3) is easily identifiable as 2^(k+1)-1. The second column can be recognized as N(N-1)/2. Other than that, the underlying formula generating the other columns and rows is rather elusive. Again, please feel free to try for yourself!
For the remainder of the paper, we will refer to S_N(k) as the sequence for N. The sequence for N=4 therefore starts by 1, 6, 25, 90,...
My wife actually found another very nice relationship in the table. Denoting by En^k the elements in the table ((N-1)-th row and (k+1)-th column), we observe that:

See the 301 value? It's 3 * 90 + 31.
A very nice relationship, but unfortunately very difficult to exploit for our purpose!

No comments:
Post a Comment